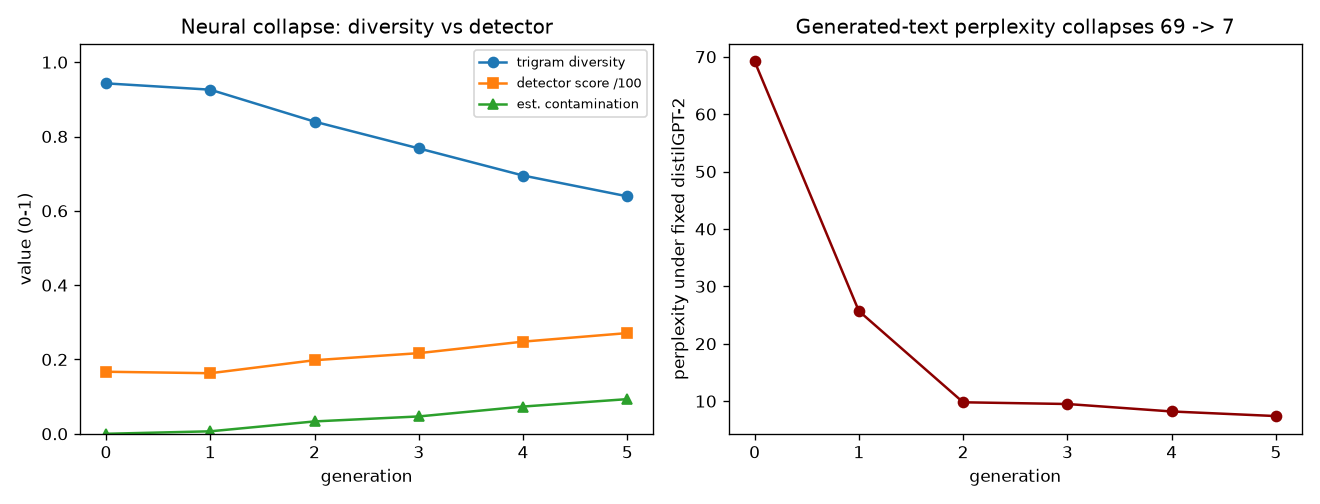
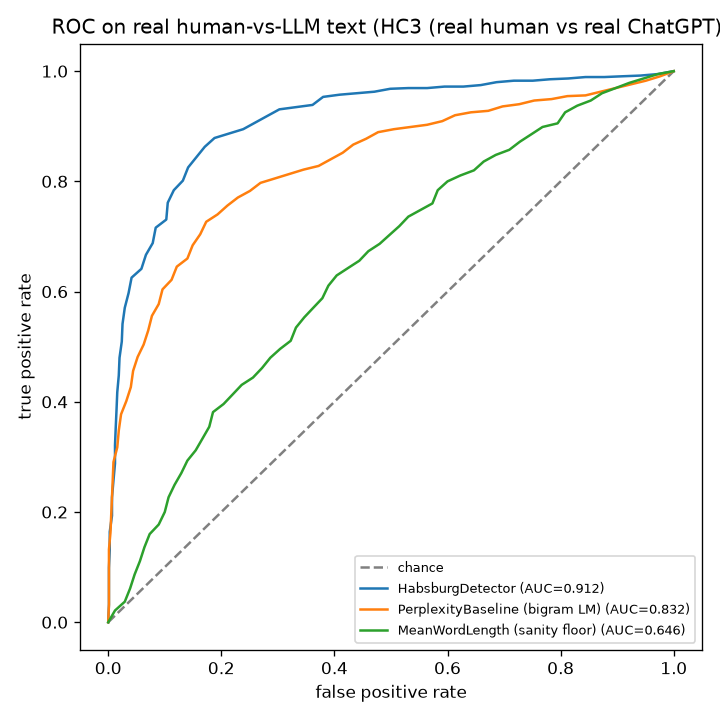
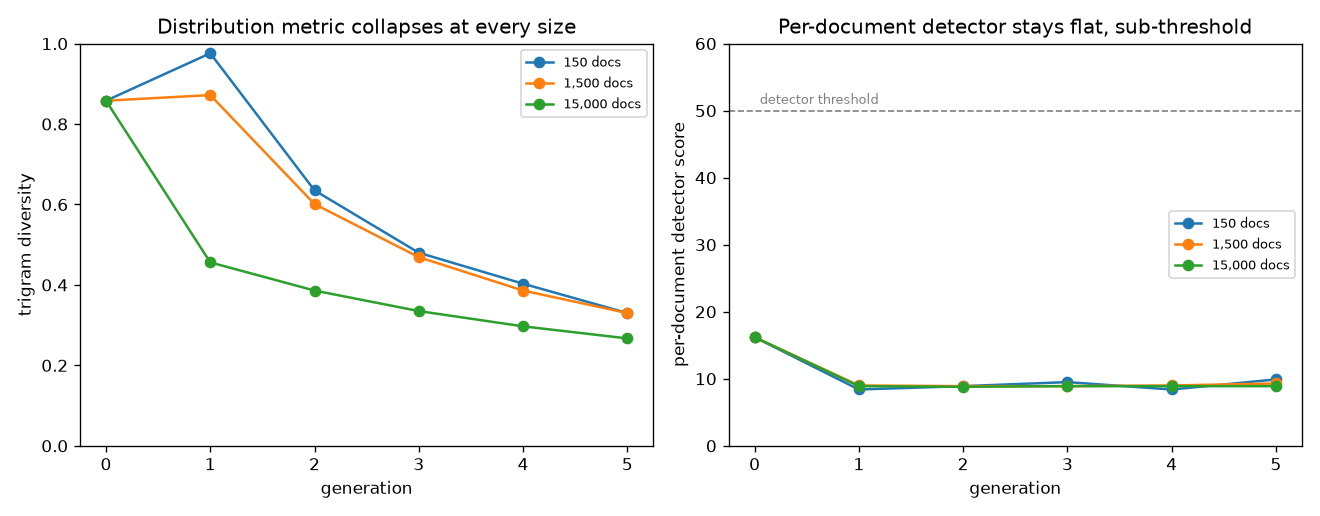
Results · real data
Detection on real human-vs-LLM text
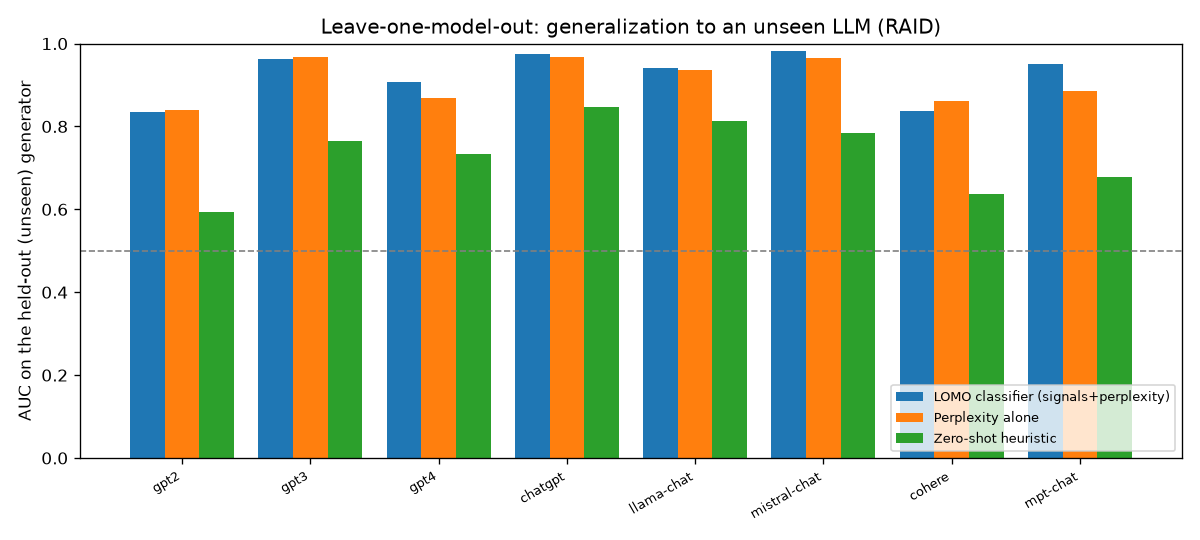
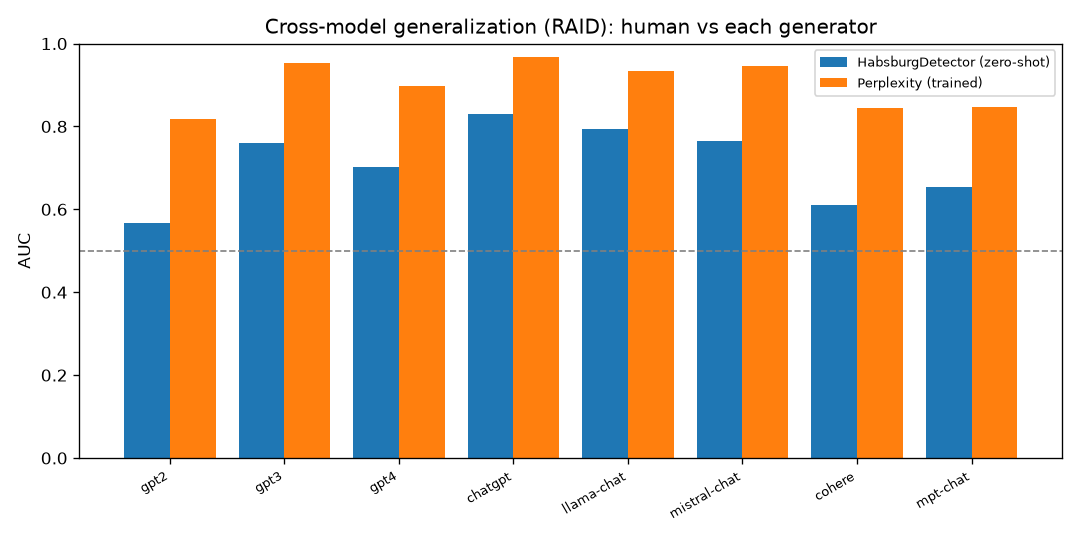
The headline — generalizing to unseen generators
| Held-out | Classifier | Perplexity | Zero-shot |
|---|---|---|---|
| Mistral-chat | 0.981 | 0.965 | 0.784 |
| ChatGPT | 0.976 | 0.968 | 0.848 |
| GPT-4 | 0.907 | 0.868 | 0.734 |
| Cohere | 0.837 | 0.862 | 0.636 |
| GPT-2 | 0.834 | 0.840 | 0.594 |
| Mean | 0.924 | 0.911 | 0.732 |
Significant across 10 seeds
Mean 0.915 ± 0.006 (95% CI [0.911, 0.920]) vs perplexity 0.903 ± 0.007 — non-overlapping CIs. Paired permutation test: +0.013, wins 10/10 seeds, p = 0.002.
An honest comparison — GLTR beats the heuristics
| Detector (zero-shot) | HC3 | RAID |
|---|---|---|
| SyntheticTextProbe (heuristics) | 0.915 | 0.724 |
| GLTR — GPT-2 log-prob | 0.995 | 0.862 |
| GLTR — GPT-2 top-10 rank | 0.995 | 0.848 |
This strengthens the thesis
A white-box likelihood detector clearly wins for detection — but it is also per-document, so it is equally blind to collapse. The gap isn't an artifact of a weak detector.